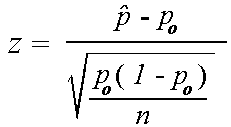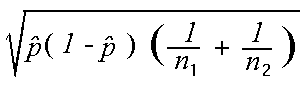Inference for Categorical Data
The analysis of categorical data generally involves the proportion
of "successes" in a given population. This may consist of estimating a single parameter, comparing
two parameters, or investigating the potential relationship between two or more categorical
variables. Note: This section addresses the first two areas -- see
the chi-square test for a discussion of the latter.
Confidence Intervals and Significance Tests for a Single Proportion
Given a simple random sample of size n from a population,
the number of "successes" X divided by the sample size n provides the
sample proportion 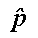 ,
an estimate of the population proportion p. This proportion follows a
binomial distribution with mean p and variance (p(1-p))/n. Since the binomial
distribution is approximately normal for large sample sizes,
tests of significance and confidence intervals
for a single proportion use a z statistic.
,
an estimate of the population proportion p. This proportion follows a
binomial distribution with mean p and variance (p(1-p))/n. Since the binomial
distribution is approximately normal for large sample sizes,
tests of significance and confidence intervals
for a single proportion use a z statistic.
Example
A marketing team wishes to evaluate the popularity of a new product in a particular city.
A random survey of 500 shoppers indicates that 287 shoppers favor the new product, 123 shoppers
dislike the product, and the remaining 90 shoppers have no opinion. Is there evidence that more
than 50% of shoppers like the product?
The sample proportion of shoppers who favor the product is 287/500 = 0.574. What is a 95%
confidence interval for the proportion? Is the proportion significantly different from 0.5?
To find a confidence interval for a proportion, estimate the standard deviation sp
from the data by replacing the unknown value p with the sample proportion ,
giving the standard error sp = 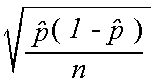 .
.
An approximate level C confidence interval for p is + z*
where z* is the upper (1-C)/2 critical
value from the standard normal distribution.
Example
In the example above, the sample proportion is 0.574. The standard error sp is
equal to sqrt((0.574(1-0.574))/500) = sqrt((0.574*0.426)/500) = sqrt(0.245/500) = sqrt(0.00049) =
0.022. The critical value for a 95% confidence interval is 1.96, so the confidence interval
for the proportion is 0.574 + 1.96*0.022 = (0.574 - 0.043, 0.574 + 0.043) = (0.531, 0.617).
To test the null hypothesis H0: p = p0 against a one- or two-sided
alternative hypothesis Ha, replace p with p0 in the
test statistic
The test statistic follows the standard normal distribution (with mean = 0 and standard deviation
= 1). The test statistic z is used to compute the
P-value for the standard normal distribution, the probability that a value at least as
extreme as the test statistic would be observed under the null hypothesis. Given the null
hypothesis that the population proportion p is equal to a given
value p0, the P-values for testing H0
against each of the possible alternative hypotheses are:
P(Z > z) for Ha: p > p0
P(Z < z) for Ha: p < p0
2P(Z>|z|) for Ha: p  p0.
p0.
Example
In the example above, the marketing team wishes to test the one-sided hypothesis
Ha: p > 0.5 against the null hypothesis that p = 0.5.
The test statistic z is equal to (0.574 - 0.5)/(sqrt((0.5)(0.5)/500)) = 0.074/sqrt(0.25/500)
= 0.074/0.022 = 3.364. The probability P(Z > 3.364) = 1 - P(Z < 3.364)
= 1 - 0.9996 = 0.0004, so this result is highly significant. The marketing team can conclude
that more that 50% of the population favor the new product.
Sample Size
An increase in sample size will decrease the length of the confidence interval without reducing
the level of confidence. This is because the standard deviation decreases as n increases.
The margin of error m of a confidence interval is defined to be the value added or
subtracted from the sample proportion which determines the length of the interval:
m = z*.
Given a guessed value p* for the proportion p, substitute
p* for p to calculate m. Solving for n gives the
expression n = (z*/m)²p*(1-p*). The margin
of error is maximized when p* = 0.5, in which case n =
(z*/2m)².
Example
Suppose the marketing team in the above example had wished to achieve a margin of error less than
or equal to 2% with 95% confidence. Assuming p* = 0.5, they calculate n
to be greater than or equal to (1.96/(2*0.02))² = (1.96/0.04)² = 49² = 2401.
This is significantly larger than the sample of size 500 taken by the intitial survey.
Comparison of Two Proportions
Like the comparison of two population means, the comparison of two
proportions p1 and p2 involves analyzing the difference between
the two sample proportions, 1 -
2. The mean of the difference between
the two proportions is the difference of the means, p1-p2,
and the variance of the difference is the sum of the variances,
(p1(1-p1))/n1 +
(p2(1-p2))/n2.
To find a confidence interval for the difference of proportions p1-p2,
estimate the standard deviation sD
from the data by replacing the unknown values p1 and p2 with
the sample proportions 1 and
2 taken from samples of size n1
and n2, giving the standard error of the difference sD =
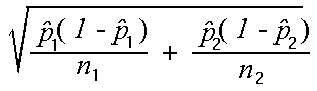
.
An approximate level C confidence interval for p1 - p2
is 1 -
2 + z*sD
where z* is the upper (1-C)/2 critical
value from the standard normal distribution.
Example
In the dataset "Popular Kids," students in grades 4-6 were asked whether good grades, athletic
ability, or popularity was most important to them. Is popularity more important to girls or boys?
What is a confidence interval for the difference?
169 girls and 166 boys were included in the survey. Of the girls, 58 ranked popularity most
important, compared to 40 of the boys. The sample proportion for girls is 58/169 = 0.34,
and for boys it is 40/166 = 0.24. A 95% confidence interval for the difference between
the two proportions is 0.34 - 0.24 + 1.96*sD, where sD =
sqrt((0.34(1-0.34))/169 + (0.24(1-0.24))/166) = sqrt(0.0013 + 0.0011) = sqrt(0.0024) = 0.049,
so the confidence interval is equal to (0.1 - 1.96*0.049, 0.1 + 1.96*0.049) = (0.004, 0.196).
Although the confidence interval does not contain 0, it is very close to zero, indicating that
the difference is not highly significant.
Data source: Chase, M.A and Dummer, G.M. (1992), "The Role of Sports as a Social Determinant
for Children," Research Quarterly for Exercise and Sport, 63, 418-424. Dataset available through
the Statlib Data and Story Library (DASL).
To test the null hypothesis H0: p1 = p2
against a one- or two-sided alternative hypothesis Ha, first compute a
pooled estimate for the parameter =
(X1 + X2)/(n1 + n2), where X1
and X2 represent the number of "successes" in each population sample.
This estimate for a single sample proportion agrees with the null hypothesis, where the two
proportions are assumed to be equal. Calculate the pooled standard error sp, equal to
.
The test statistic z = (1 -
2)/sp
follows the standard normal distribution (with mean = 0 and standard deviation
= 1). The test statistic z is used to compute the
P-value for the standard normal distribution, the probability that a value at least as
extreme as the test statistic would be observed under the null hypothesis. Given the null
hypothesis that the population proportions are equal, the P-values for
testing H0
against each of the possible alternative hypotheses are:
P(Z > z) for Ha: p1 > p2
P(Z < z) for Ha: p1 < p2
2P(Z>|z|) for Ha: p1 p2.
Example
To test the difference of the proportions of girls and boys who rated popularity most important,
first compute the pooled estimate =
(58 + 40)/(166 + 169) = 98/335 = 0.29. The pooled standard error is equal to sqrt((0.29(1-0.29)/(1/166 + 1/169))
= sqrt(0.206*0.012) = sqrt(0.0025) = 0.05. The test statistic z = (0.34 - 0.24)/0.05
= 0.10/0.05 = 2. Since this is a two-sided hypothesis, we are interested in the probability
2P(Z > 2) = 2(1 - P(Z < 2))
= 2(1 - 0.9772) = 2(0.0228) = 0.0456. This is significant at the 0.05 level, although it is not
significant at the 0.01 level.